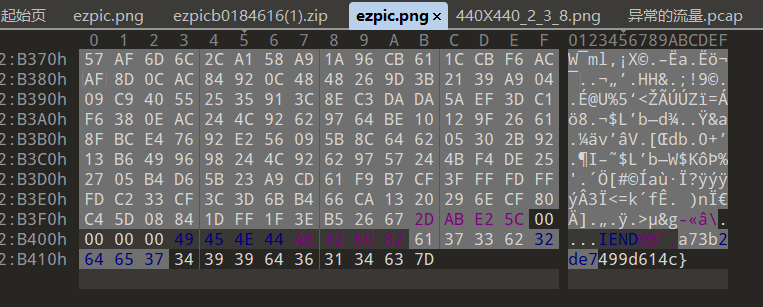
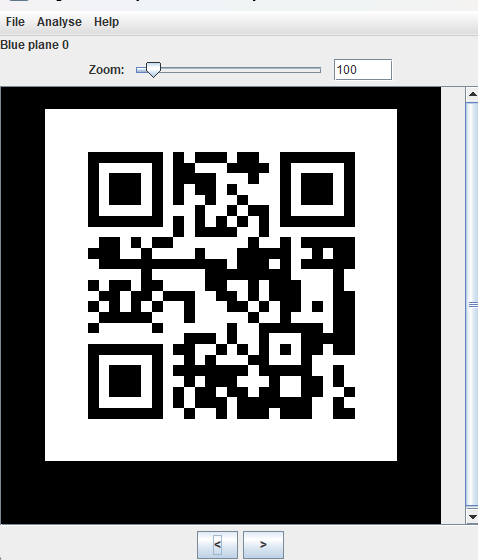
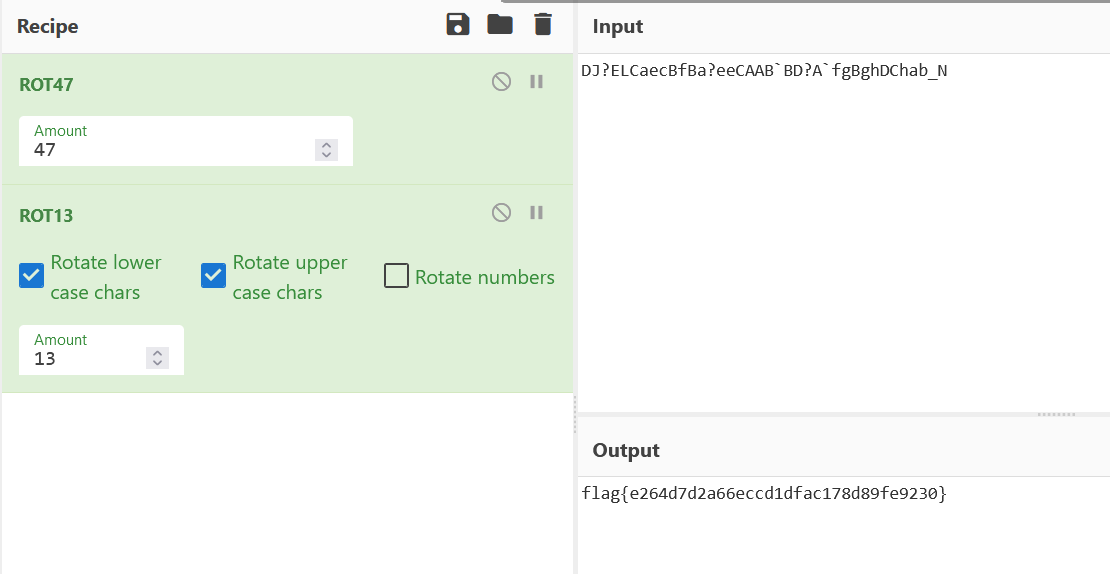
## 去除收尾空白字符以\n分隔 # data=[[int(i) for i in v.split(" ")] for v in data.split('\n')] # print(data) lines = data.strip().split('\n') # 每行进行分割 split = [line.split(" ") for line in lines] # 将字符串列表转换为整数列表 data = [[int(i) for i in line] for line in split] # print(data) maze = [data[0][0]]
# 初始化数据
# 对数据进行处理,确定l1,l2,l3 def find_matching_value(n1, n2, list1): return next((d3 for d3 in list1 if n1 + n2 == d3 or n1 - n2 == d3), None)
# 进行后续数据进行批量处理,并将符合条件的添加到数组中 for da2 in data[1]: for da3 in data[2]: if find_matching_value(data[0][0], da2, [da3]): maze.append(da2) maze.append(da3)
for i in range(3, 100): newvalue = find_matching_value(maze[i - 2], maze[i - 1], data[i]) print(maze) if newvalue is None: print("nonono!") else: maze.append(newvalue)
import requests s = requests.Session() chal_url = 'http://172.22.128.4:5000/' datas = s.get(chal_url).text data = [list(map(int, v.split(" "))) for v in datas.split("<br><br>")[0].split("<br>")]
lines = data.strip().split('\n') # 每行进行分割 split = [line.split(" ") for line in lines] # 将字符串列表转换为整数列表 data = [[int(i) for i in line] for line in split] # print(data) maze = [data[0][0]]
# 初始化数据
# 对数据进行处理,确定l1,l2,l3 def find_matching_value(n1, n2, list1): return next((d3 for d3 in list1 if n1 + n2 == d3 or n1 - n2 == d3), None)
# 进行后续数据进行批量处理,并将符合条件的添加到数组中 for da2 in data[1]: for da3 in data[2]: if find_matching_value(data[0][0], da2, [da3]): maze.append(da2) maze.append(da3)
for i in range(3, 100): newvalue = find_matching_value(maze[i - 2], maze[i - 1], data[i]) print(maze) if newvalue is None: print("nonono!") else: maze.append(newvalue)
def tel_check(tel): number = tel[:3] + '*' * 4 + tel[-4:] # 前3位+****+后4位 # print(number) return number
# out = open('out1.txt', 'w', encoding='utf8', newline='\n') with open('out1.txt', 'w', encoding='utf8', newline='') as out: with open('person.txt', 'r', encoding='utf-8') as infile: lines = infile.readlines() for i, line in enumerate(lines): line = line.strip() if line: parts = line.split(',') if len(parts) == 3: name = name_check(parts[0].strip()) sfz = sfz_check(parts[1].strip()) tel = tel_check(parts[2].strip()) masked_line = f"{name},{sfz},{tel}" if i < len(lines) - 1: # 如果不是最后一行,添加换行符 masked_line += '\n' out.write(masked_line)
with open('out1.txt', 'rb') as f: md5_value = hashlib.md5(f.read()).hexdigest() print(md5_value)
def getIDNumber(line): match = re.search(r"\b(?:\d{17}[0-9X]|\d{15})\b", line) return match[0]
def getBirth(idNumber): # 从身份证中获取生日 data = re.compile(r"^\d{4}-(?:0\d|1[0-9]|2[0-3])-(?:0[1-9]|[12][0-9]|3[01])$") return data
def read_csv(file_path): result = [] with open(file_path, 'r', encoding='utf-8') as infile: reader = csv.reader(infile) next(reader) # 跳过表头 for row in reader: if len(row) >= 4: data = { '姓名': row[0], '性别': row[1], '出生日期': row[2], '身份证号': row[3] } result.append(data) return result
input_data = read_csv(input_file) processed_data = [] for row in input_data: # Extract birth date from ID card id_birth_date = row['身份证号'][6:14] formatted_birth_date = f"{id_birth_date[:4]}-{id_birth_date[4:6]}-{id_birth_date[6:]}"
if (formatted_birth_date == row['出生日期'] and check_id_number(row['身份证号']) and getGender(row['性别']) and extract_gender(row['身份证号']) == row['性别']): processed_data.append(row)
# 计算差异 difference = [row for row in input_data if row not in processed_data]
# 写入差异数据到文件 with open(output_file, 'w', encoding='utf-8', newline='') as outfile: writer = csv.DictWriter(outfile, fieldnames=['姓名', '性别', '出生日期', '身份证号']) writer.writeheader() # 写入表头 for row in difference: writer.writerow(row)
print(f"Difference saved to {output_file}") with open('out.txt', 'rb') as f: md5_value = hashlib.md5(f.read()).hexdigest() print(md5_value)